蛋白质复合物由蛋白质-蛋白质互作(protein-protein interaction,PPI)组装而成,受到各种机制的动态调节,对PPI的研究可以揭示各种细胞过程的潜在机制,并揭示它们的失调如何导致疾病,从而为开发新的治疗方法、识别新的药物靶点提供先验知识指导。2018年开发的热临近共聚集(thermal proximity co-aggregation,TPCA)方法率先使用热蛋白质组学分析来研究PPIs的动力学和在原位大规模表征蛋白质复合物,目前已获得广泛应用。然而,传统的TPCA方法需要大量的样品和较长的计算时间,并且一组10标TMT试剂仅能用于标记一个条件下的TPCA实验,因此实验组和对照组样品必须在不同时间通过质谱进行分析,容易引入批次效应。

因此,TPCA的发明者,南方科技大学 Chris Soon Heng Tan教授团队优化了TPCA方法,提出了一个简化版本Slim-TPCA,使用更少的温度点将通量提高了3倍以上,通过算法优化,更好地识别PPIs的动态变化,提高统计功效,并且通过结合SISPROT样品前处理技术显著减少样品使用量。该成果已于2023年11月发表于Nature communications。
一、Slim-TPCA温度点的优化
在传统TPCA方法中,需要10个梯度温度,需要多套TMT试剂来标记和分析不同条件的样品,容易引入批次效应。因此作者首先评估了使用更少的温度点来分析PPI,作者发现虽然较少温度点的预测能力略有下降,但仍在可接受范围内。接着,作者评估了哪种相似性度量方法更适合在温度点较少的情况下使用,在曼哈顿距离、切比雪夫距离、余弦距离、皮尔森相关系数、PISA和ΔTm中,皮尔森相关系数会随着温度点减少迅速恶化,而曼哈顿距离在较少温度点上有最佳的预测能力。最终,作者确定了最适合的3个温度点组合(37℃、49℃、58℃)和4个温度点组合(37℃、46℃、55℃、61℃),并且已知数据对比发现两者高度相关。
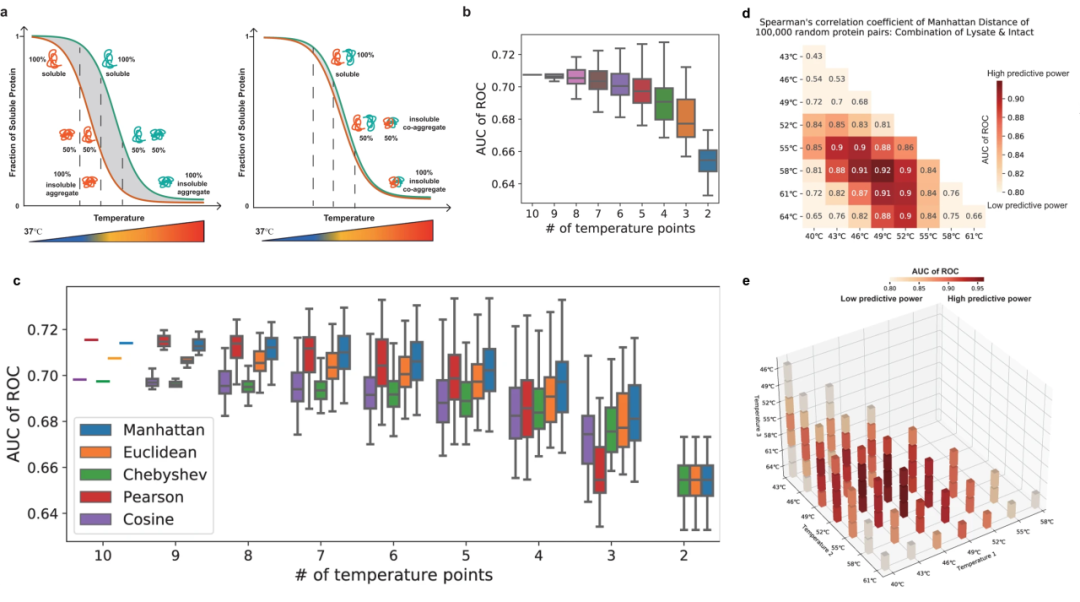
图1 Slim-TPCA温度点的优化
二、算法优化,提高统计功效
TPCA通过和10000个随机生成相同大小的基准蛋白质组数据的p值比较来识别各种条件下的关键蛋白质复合物。与传统TPCA方法中的绝对距离算法相比,作者优化后的相对距离算法对计算CORUM配合物的TPCA特征与绝对距离算法计算的结果在10个温度点和4个温度点都保持较高的相关性(r=0.93/0.92)。并且,相对距离算法还确定了更高百分比的与细胞周期、DNA加工相关的蛋白质复合物,例如参与DNA复制的RFC复合物被相对距离算法识别而被绝对距离算法遗漏。此外,传统10000个随机生成的蛋白质组数据获得离散的p值,占用大量计算时间,作者使用基于拟合Beta分布的p值算法优化了TPCA工作流程,以较小的样本量拟合特定的数据分布估计p值,观察到了更多动态调节的蛋白质复合物,同时新算法采样处理的时间只需要原始采样处理时间的1%。
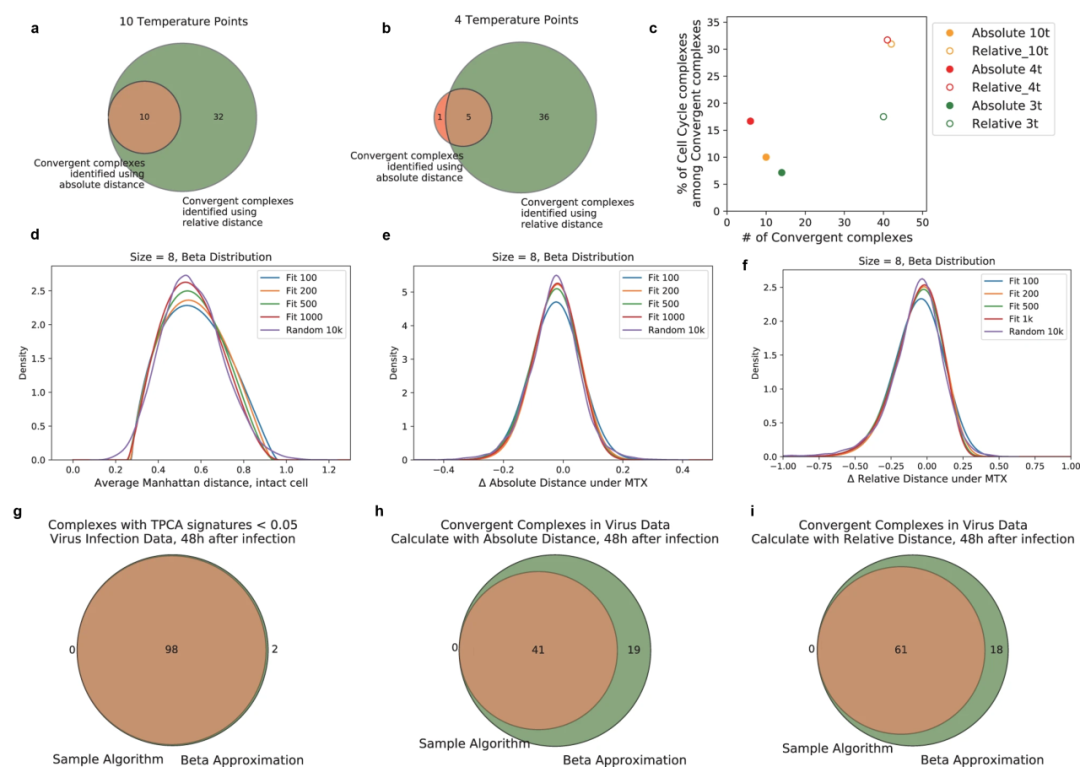
图2 相对距离算法和拟合Beta分析的p值算法优化
三、Slim-TPCA识别响应葡萄糖
剥夺的动态调节复合物
为了验证改进后的Slim-TPCA的适用性,作者将其用于研究CORUM注释的蛋白质复合物在葡萄糖剥夺下的动力学。针对5个葡萄糖剥夺时间点,分析K562细胞内蛋白质复合物在三个温度点的变化情况,共三组生物学重复,每组重复用一套16表TMT试剂标记。结果表明,参与生物学过程的蛋白质复合物被注释为葡萄糖饥饿相关,并且细胞质和线粒体核糖体的解离增加也与葡萄糖饥饿期间蛋白质翻译的衰减一致。同时,作者发现许多参与呼吸或呼吸相关的线粒体蛋白复合物以及涉及囊泡的蛋白质转运复合物被调节,表明TPCA还适用于位于膜结合细胞器内以及膜相关的蛋白质复合物分析。
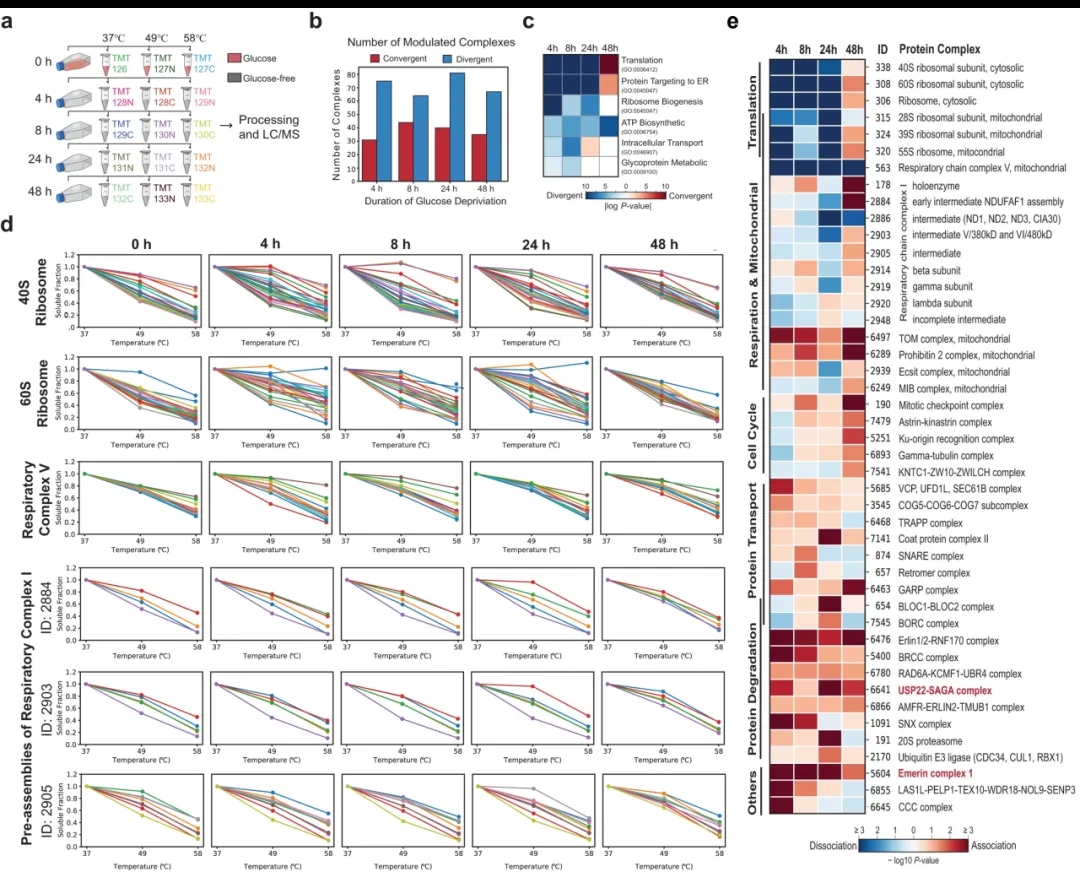
图3 Slim-TPCA识别响应葡萄糖剥夺的蛋白质复合物
四、总结
综上所述,作者对原始的TPCA方法进行了升级,提出了新的Slim-TPCA,通过使用更少的温度点和改进的数据反卷积算法,将通量提高了三倍以上,统计计算时间减少了100倍,并且有更高灵敏度识别蛋白质复合物,允许在细胞条件下大规模表征蛋白质复合物,相关的数据分析算法作者也整理并发布了相关的Python包供相关研究者使用。
原文链接:
https://www.nature.com/articles/s41467-023-43526-2
深圳市贝普奥生物科技有限公司是一家于2022年1月在深圳成立的蛋白质组学研发型高科技公司。作为蛋白质组学上游市场解决方案提供商,公司致力于对蛋白质组学领域的研发成果进行商业开发及转化。团队以受多项专利保护的蛋白质组学前处理系列产品为切入点,通过临床功能蛋白质组学技术平台为目标市场提供全流程解决方案。
公司核心成员在蛋白质组学、肿瘤生物学领域获得重大科研成果,超半数员工拥有博士、硕士学位及海外研究经历。充满创造力的团队立足于大湾区,服务全球,专注于降低蛋白质组学分析技术难度,提升其在创新标志物和创新药物研发全链条中的应用,以蛋白质组学技术为重大疾病提供精准诊疗策略。

 公众号
公众号